Make it dynamic!

•
April 17, 2026
SLayer’s intended audience is agents and humans formulating ad hoc queries, not dashboards replaying the same request day in, day out.
For the dashboard case, pre-computing every aggregate can be a crucial performance booster, and that requires specifying them all upfront. For the ad hoc case, it’s the wrong trade-off — the query you need next is the one nobody foresaw when the model was written, so the priority shifts to how easily you can shape the query at the moment you write it.
The rest of this post is a tour of what “shape it at the moment you write it” actually means in SLayer.
Query-time transforms and aggregations
The first form of dynamism is query-time transforms: expressions defined right inside the query, not the model. Time-shifted measures, period-over-period changes, cumulative sums, ratios between measures — all computed at query time, no model edit required. The time-specific family (time shifts, change, last) is covered in depth in the time dimensions post.
So now in the context of a query with a known time dimension and known granularity we have a natural “previous” concept. This means we also have a natural “change” concept, which in SLayer we can express as a simple query-time change(x) transform that needs no additional arguments, and just returns the change of its argument from one period (defined by the time dimension and granularity of the query) to the next one.
Closely related is query-time aggregation. A measure in SLayer is just a named row-level expression with the choice of aggregation deferred to query time.
At the semantic level this is the natural framing: aggregation is a property of the question, not of the measure. Asking for the sum, average, or median of the same underlying quantity is the same question at different resolutions, so a semantic layer should let you pick the resolution in the query, not bake a new named measure into the model for each combination.
In contrast, most semantic layers force you to pre-declare one measure per (expression × aggregation) pair, which multiplies the model surface area fast.
⭐ Star on GitHub · Quick start · Open an issue
SLayer’s answer is colon syntax: revenue:sum, revenue:avg, revenue:quantile(0.25). Custom aggregations defined with SQL templates and parameters (weighted averages, percentiles, trimmed means) plug in the same way.
Contrast this with pre-definition-heavy semantic layers. In something like Cube.js, every new shape of question requires a pre-declared measure or dimension in the cube: time-shifted revenue is one measure, its change over period another, the same pair repeated for every granularity and time column you care about, plus every bucket dimension you might plausibly want. The model definition explodes combinatorially — and the resulting thing has to fit into an agent’s context window.
SLayer trades pre-computation for the ability to write the exact query you need, once, in the space where you were going to write it anyway. But that is not all!
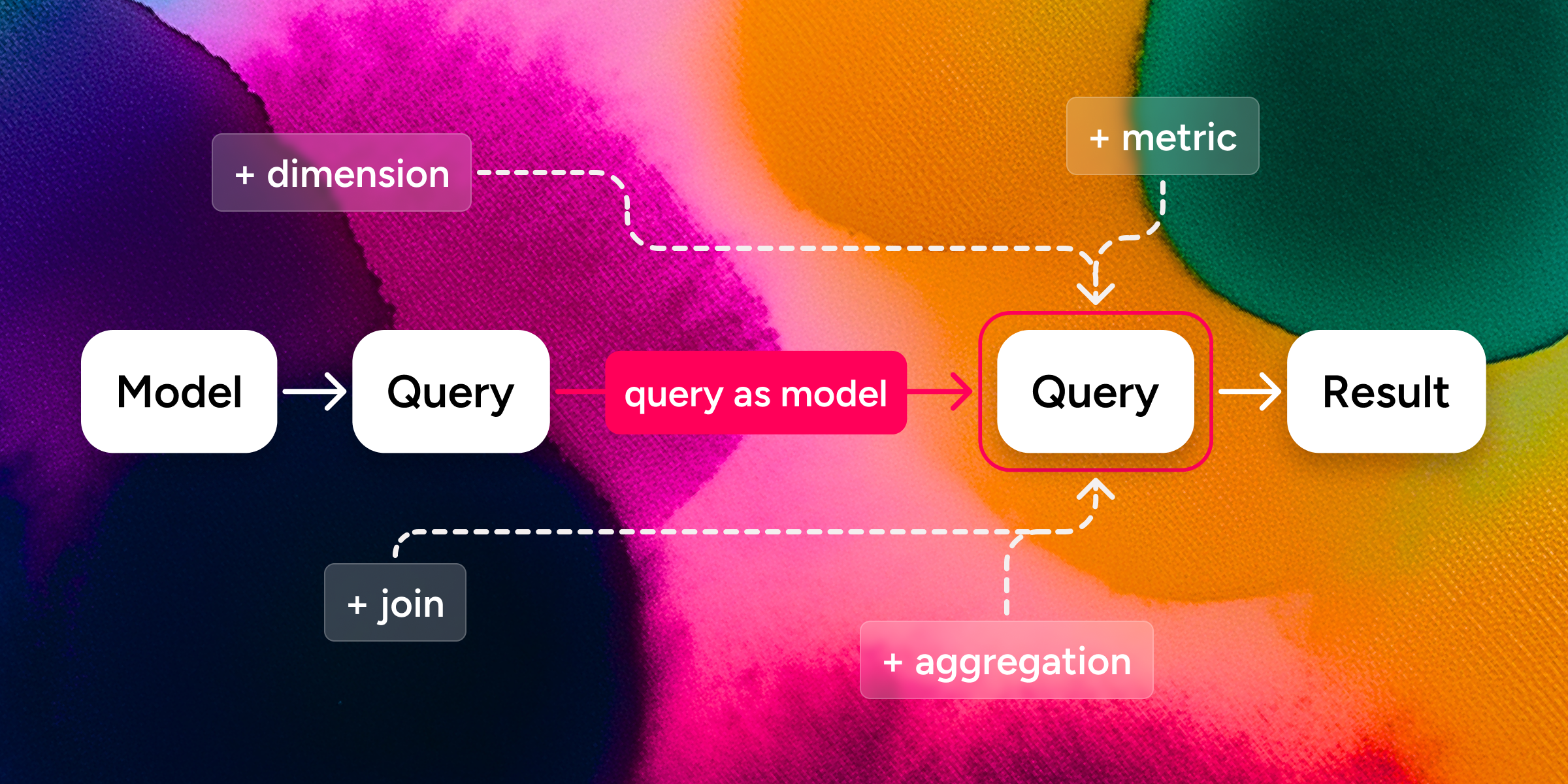
Extending the model inline
The second form of dynamism is extending the model for the lifetime of one query. Sometimes a dimension only makes sense for the question you’re asking right now: group by whether some floating-point number is positive, bucket a continuous value by derived category, filter on a condition that won’t come up again.
The semantic concept is trivial; the SQL that expresses it is a view, a dbt model, or a CTE chain, and making a commit to a source controlled config repo to change any of those for a one-off is disproportionate.
SLayer’s answer are model extension semantics: when constructing a query, the source_model can be a plain model name, or it can be that model name plus extra dimensions, measures, filters, and joins appended for the lifetime of this single query.
The persisted model stays untouched.
Dynamic joins — the surprising one
You might reasonably ask why one would want to add joins at query time. If there’s a relationship between this model and another, shouldn’t it live in the model definition?
Often, yes. But not always — because queries themselves can be used as models. A SLayer query resolves to a SQL query, and SLayer’s introspection already turns any SQL query into a model by generating dimensions and measures from its columns.
Dynamic joins are what stitch a query-as-model back into a bigger query.
Multistage queries fall out of two simple pieces
Put queries-as-models together with inline joins and you get multistage queries — not as a bolt-on with its own syntax, but as a natural consequence of the two features above. Two patterns this makes easy, both of which are genuinely awkward in most semantic layers:
- Nested aggregation: sum revenue per store, then average those store totals across months or regions. A single SQL pass can’t express this; SLayer expresses it as a two-element query list where the outer query references the inner by name.
- Grouping by a calculated dimension: bucket customers by their total spend, then count how many fall in each bucket. The bucket depends on an aggregate — so the inner query computes the totals, and the outer query’s
source_modelis a adding aCASE WHENdimension over the inner query's field.
Each of these is simple at the semantic level and non-trivial at the SQL level. That’s exactly the gap a good semantic layer should close — and SLayer closes it in the query, not the model, saving time and agent tokens and keeping the model small enough to fit.
Here is the nested-aggregation example, written out in full. The inner query computes monthly revenue per store; the outer averages across months per store:
[
{
"name": "monthly_store_revenue",
"source_model": "orders",
"fields": ["order_total:sum"],
"dimensions": ["stores.name"],
"time_dimensions": [{"dimension": "ordered_at", "granularity": "month"}]
},
{
"source_model": "monthly_store_revenue",
"fields": ["order_total_sum:avg"],
"dimensions": ["stores.name"]
}
]
Two queries, one list. order_total:sum from the inner query becomes the field order_total_sum in the outer (colon → underscore), aggregable again via the same colon syntax as any other measure. See the multistage queries docs for the calculated-bucket pattern and further examples.
What would it take to ask this question in the semantic layer you’re currently using?